Prose_我的画像:使用ChatGpt 4.0辅助文本分析
我一直想对自己的日记与博文做一个系统的定量分析,但限于精力,始终未抽出功夫。最近稍有空闲,即着手做了这件事。如果说一个人的精神发育史就是他的阅读史,那俏皮些讲,对自我文字痕迹的分析,亦无妨视为是对自我的民族志。从2015年至2024年,近十年的分析跨度,基本反映了我本科以来的思想变化。
这篇分析的另一特殊处,则是我没有主动coding,大部分的代码工作(80%以上)是ChatGpt 4.0所完成的。按照社会科学的培养模式,我认为其代码能力已不输于很多优秀院校的高年级本科生,作为学术助手,能够极大简化枯燥的数据处理流程。当然,现阶段的大模型仍然存在一定问题,比如在数据分析时,Gpt自行发挥的结果往往不符合预期,更重要的是通过Prompt反馈Gpt我们所需要的图形或模型结果,另如Gpt有时难以处理一些程序报错问题,需要程序外的排查。
事实上,上述也反映了Gpt虽能简化我们的coding工作,但目前的工作流仍是一种人机间持续的反馈与交互过程,这与工业时代依旧存在极大的共通[1]。因而,尽管Latour所讨论的物与人的联接,在形式上似乎更加复杂、多样,但“我们从未现代过”也不算过时。
我的自画像:博文与日记
由于博文(Post)与日记(Diary)并不相同,如下统计图谱均分别绘制,其中博文数据包括日记数据。后不再赘述。
一、博客的逐日活动
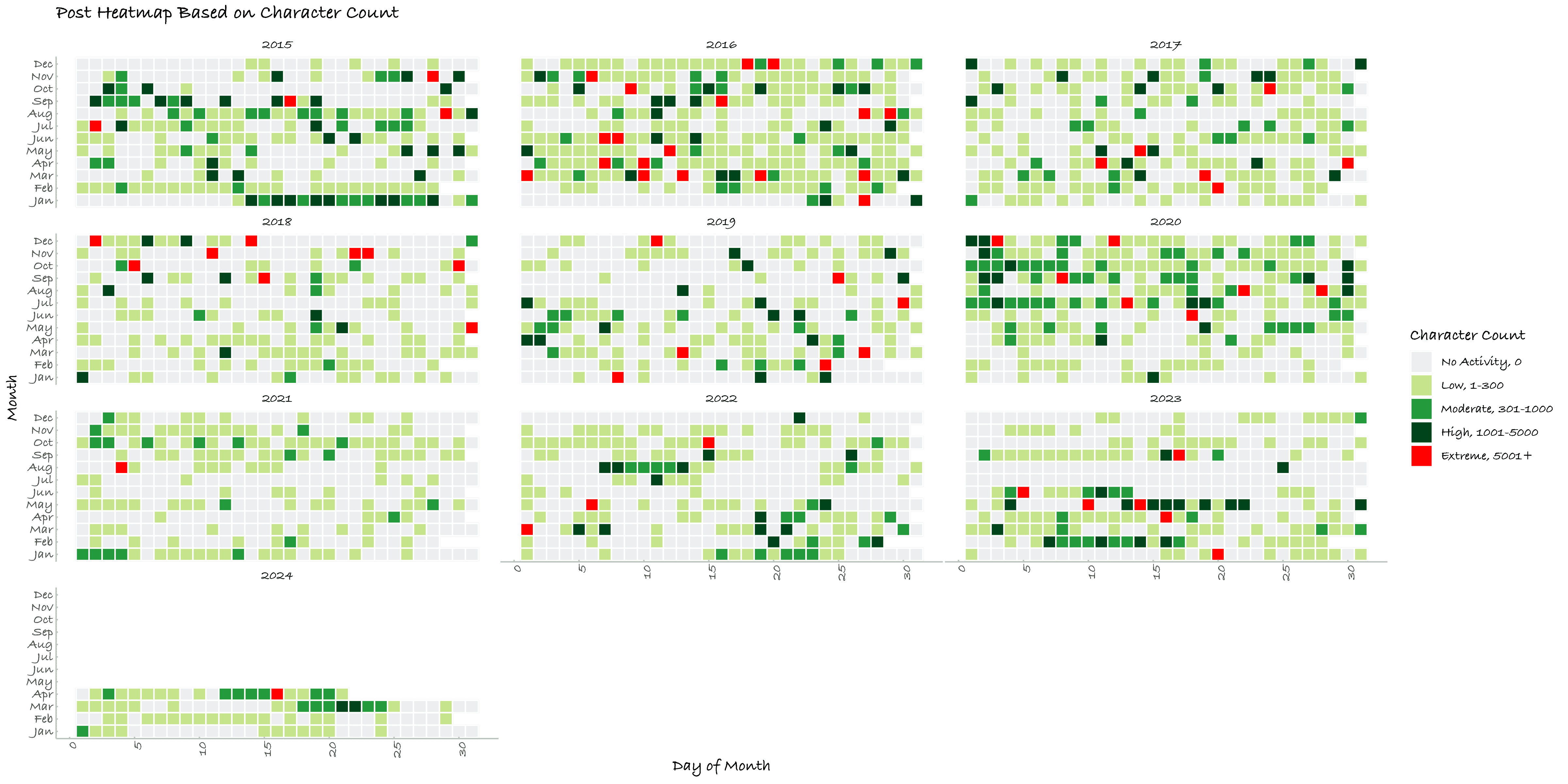
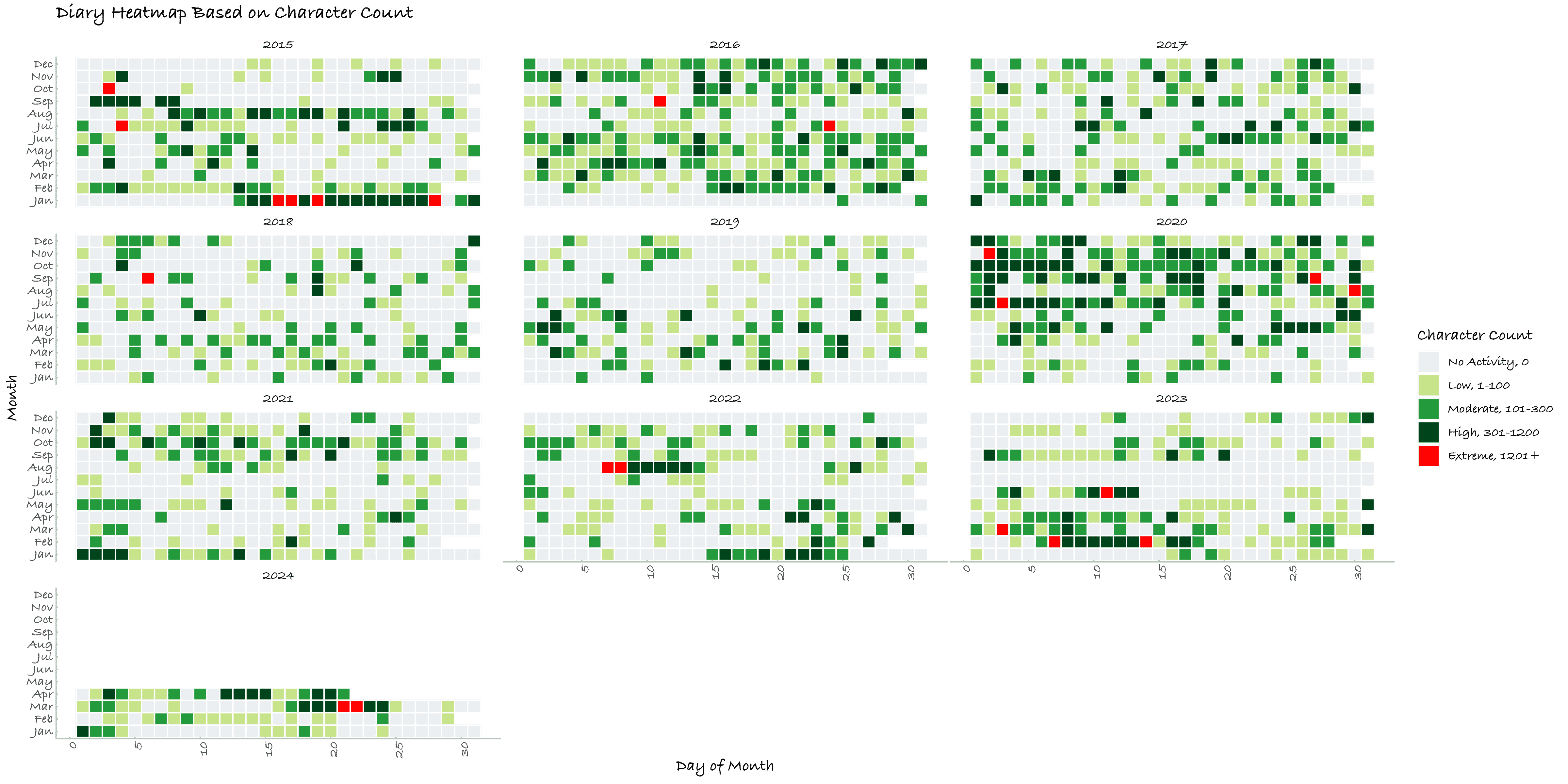
二、博客的逐季度活动
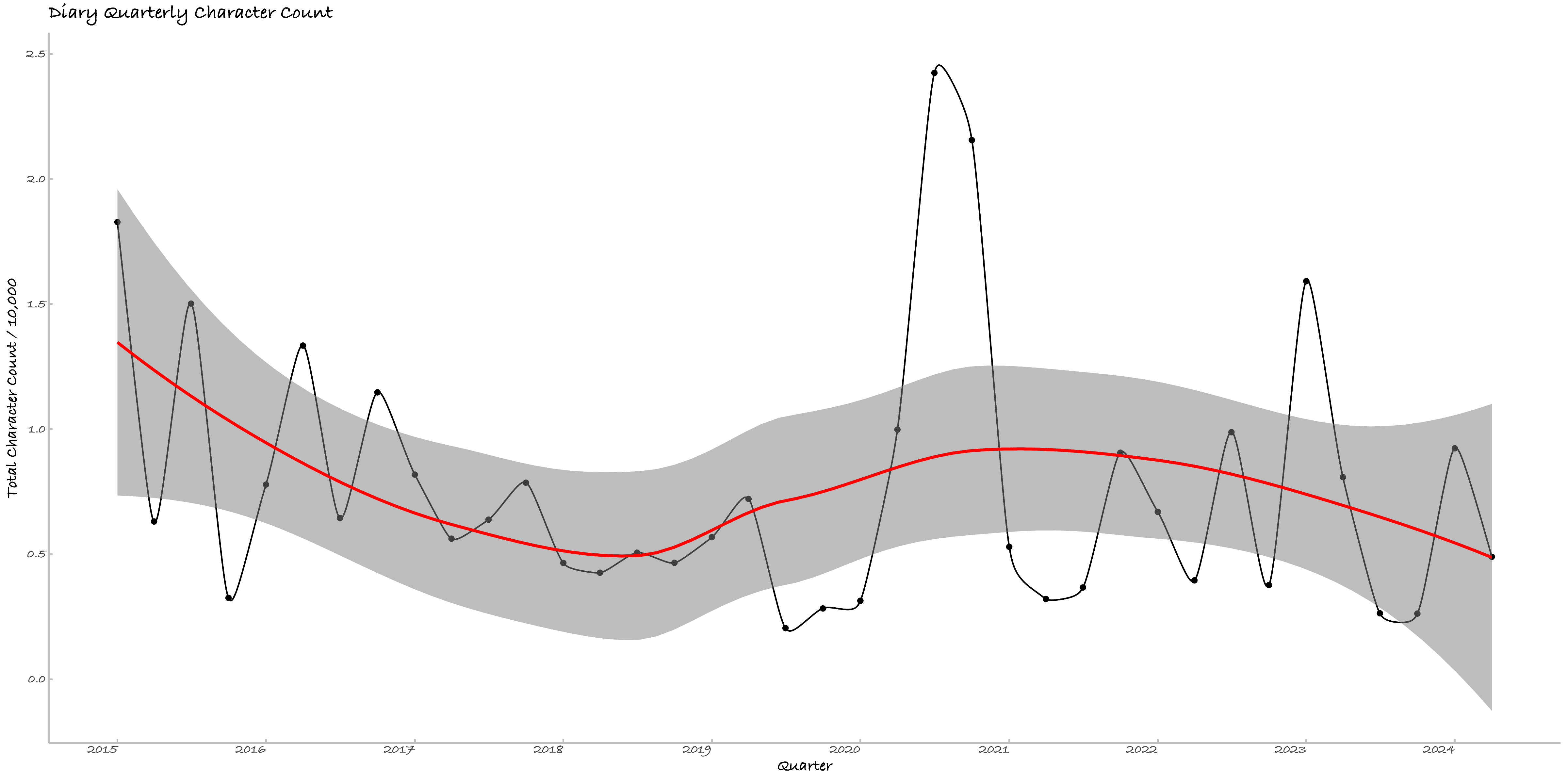
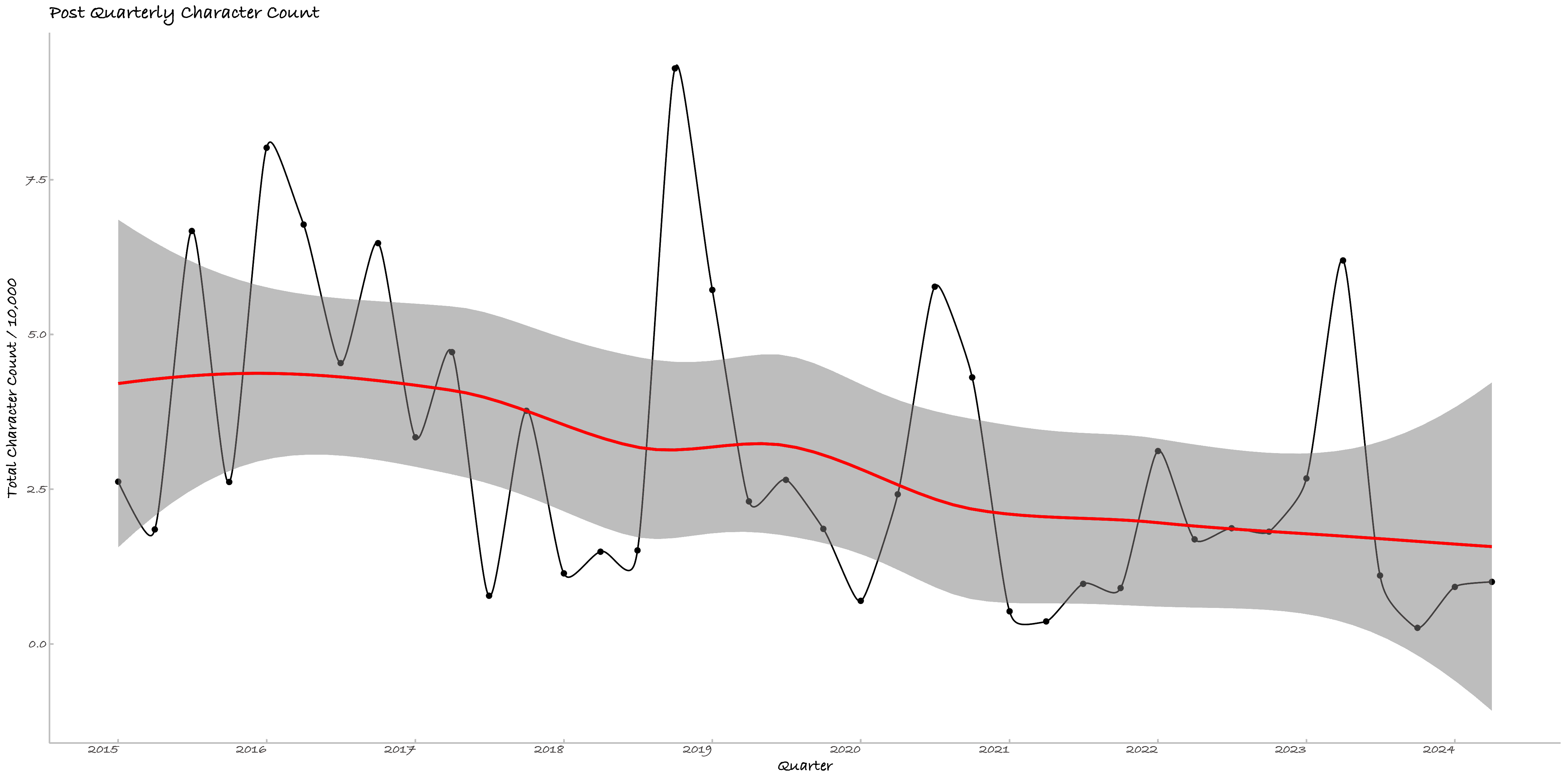
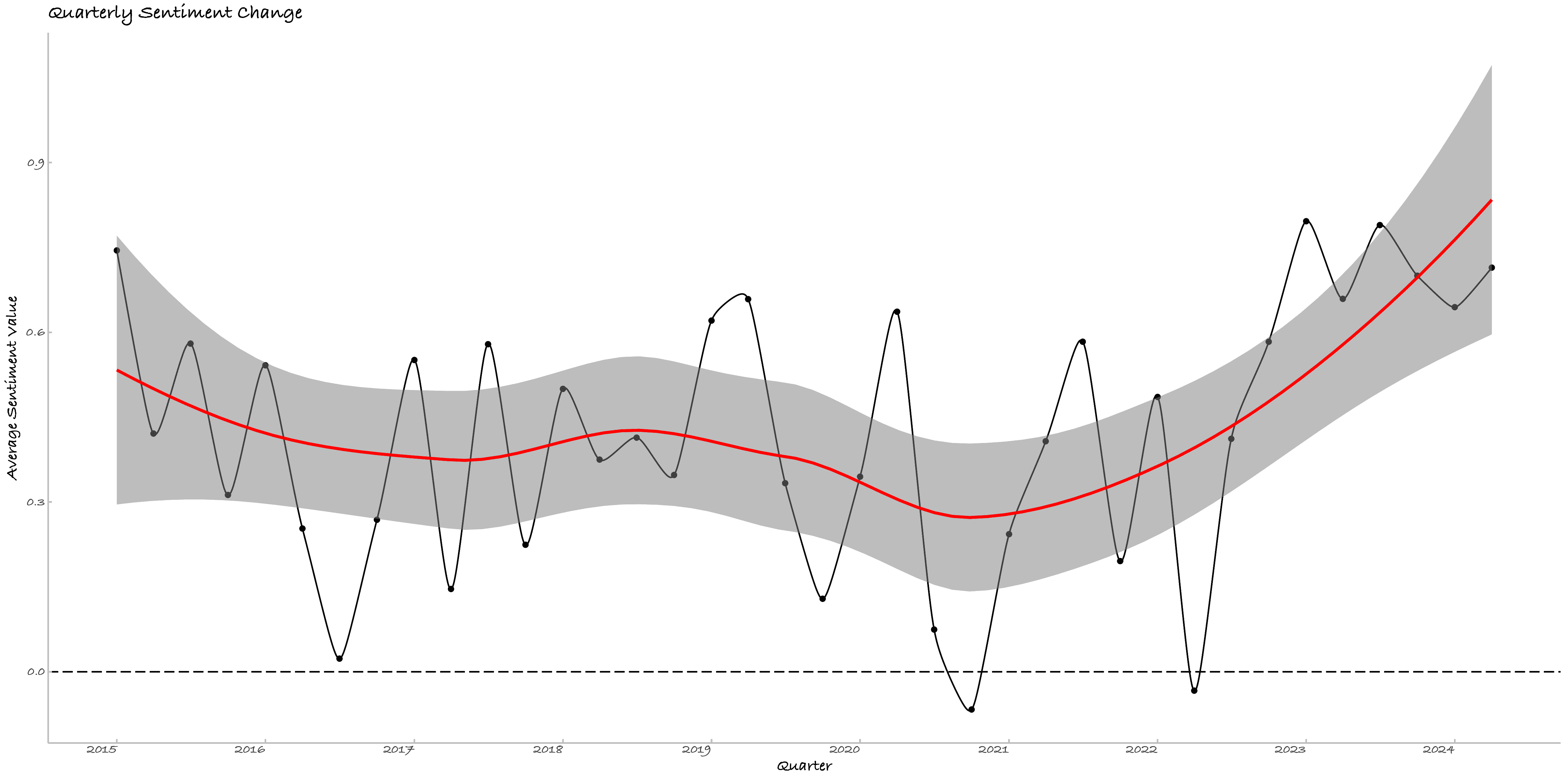
三、日记的逐季度情绪变化
本节调用了百度情感分析接口[2]以分析日记情绪变化,剔除NA后[3]有1503日被有效识别。按-1为消极、0为中立、1为积极,下图是我的情绪变化。数据化的情绪变迁与我的心理日程基本符合。
有三个有意思的事情,其一是情绪倾向比我预想的要积极很多,这可能是因为百度识别的误差,但也说明俺还算阳光男高!其二是与逐日活动的对照很有意思,2020年的偏消极的情绪与较多的记录,确为难忘的一年。
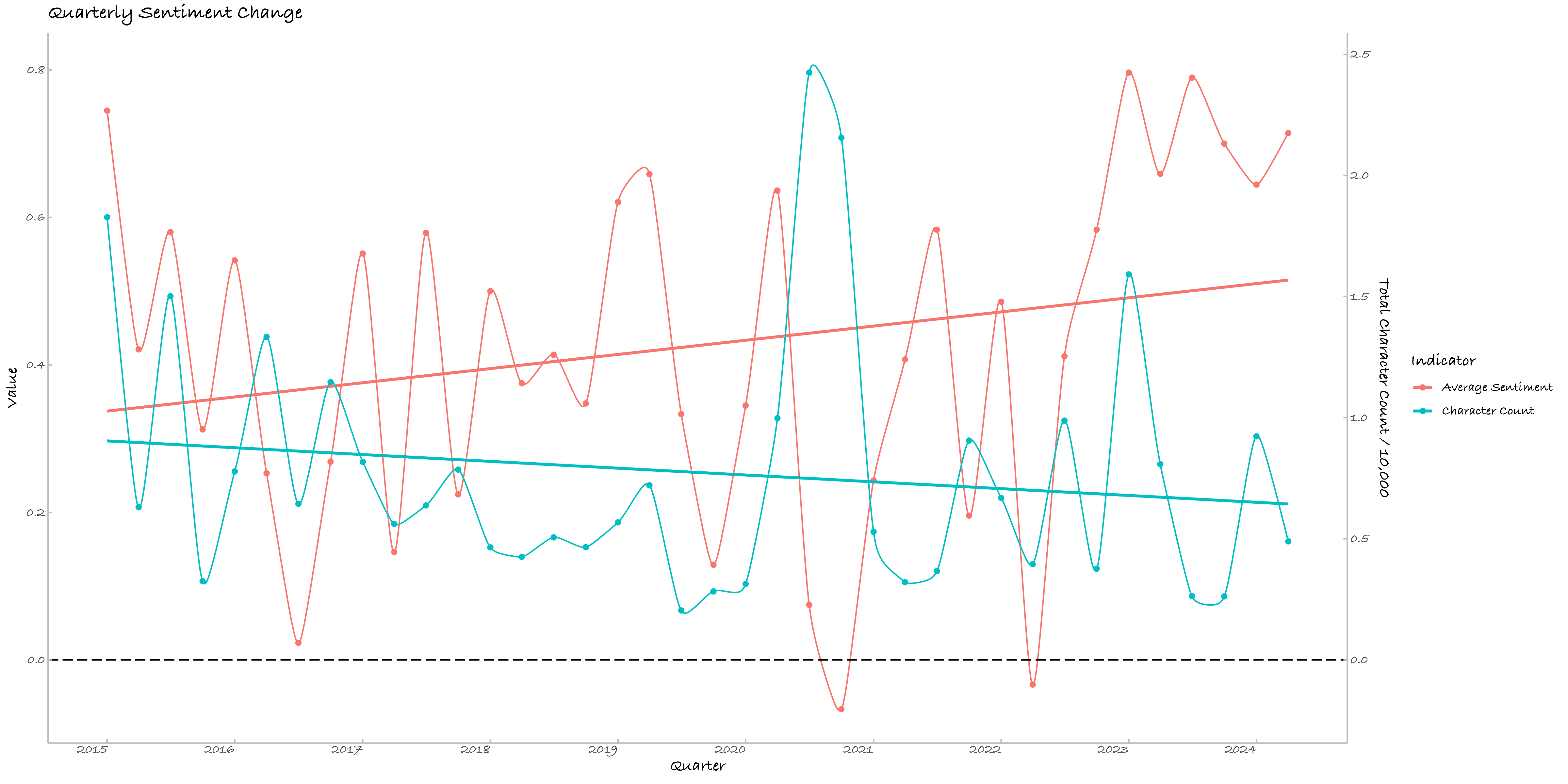
其三要单独列一段,我对季度情绪均值与季度字符数及其二次项拟合,模型显示截距项显著、二次项模型边际显著。截距显著说明情感均值不为零(这不废话么!)。二次项的显著性(P值 = 0.0920)让我们不得不面对一个可能的残酷现实:快乐的男高越写就越悲伤(或许他们是在搬砖),或者是越悲伤的诗人越勤奋(这不是诗人穷而后工嘛!)。这段情感的起伏与字符数的关系可以用以下的二次回归方程来描述:
其中 是以万为单位的字符数。根据模型,情绪均值首先随写作量的增加而上升,但达到某个临界点后,情绪就开始走下坡路了。峰值的计算显示,当字符数达到约 万字时,情绪均值达到最高点约 。超过这个点,每增加1万字,情绪均值的降幅可以描述为:
考虑到情绪均值的区间是,这样的变化幅度确实是颇为恐怖。以俺十年的亲身经验来看,当你每季度的日记字数接近1万时(大约每天113字),便是时候停笔了,不然接下来的路,真是会越走越忧郁。
| 参数 | 估计值 | 标准误差 | t 值 | P 值 |
|---|---|---|---|---|
| Intercept | 0.2882 | 0.1236 | 2.331 | 0.0256 * |
| character_count | 0.3945 | 0.2691 | 1.466 | 0.1516 |
| I(character_count^2) | -0.1919 | 0.1108 | -1.732 | 0.0920 . |
四、博客的逐年关键词
本节的上图为博文关键词,下图为日记关键词。明显区别是学术梦碎2024,近两年关键词的变迁很好地反映了我的关注点变化,其一是从社会学转入人口学,其二是业余生活因在京畿地区,参览了很多的古建筑和佛造像。四月廿四日晚,我和孙畅亦聊起我这两年的转变,其一便是将工作和生活分开,其二便是我的审美会追求一些永恒性的东西,佛造像及其背后的文化,在人类个体短暂的生命尺度里,是一种具有永恒性价值的地标,尽管这一地标及其内涵在不断流变。


ChatGpt日志与代码[4]
一、日记数据:多日期录入
在本节,我将展示如何使用ChatGpt来实现数据录入,在各轮次背后,是不断将报错反馈给Gpt,以帮助改进。
Round 1
指令:现有多个年份的文档,我希望对这些文档进行文本分析,这些文档遵循基本一致的书写规则,我将提供给你一个范本,以及相应的书写规则,请提供我必要的r语言分析代码。
1、同时有以“Diary_”为开头的,命名的日记共40份。
2、每份日记,文本的开头均有上、下两个“—”,被包含的内容是文本的基本属性。包括如tags、date等
3、每份日记遵循,以"### “开头,作为每日date以及每日的内容概述title,日期下的第一行是可以被读取的正文,作为该日的内容content,日与日的”### “之间均空一行,以进行分离。注意,这里有空行,是指date+title+content、date+title+content之间,为了分割,而存在的空行。
4、对于3有进一步说明。第一,有时使用了图片或其他超链接,会有空行出现,但每天的日记是以”### “为标准的;第二,有时使用”#### “作为每日日记的二级标题,但这仍然隶属于该日内容;第三,有时部分以”### “为开头的日期不含标题,请以空白处理。
5、在部分以Diary_为开头的文件中,我没有设置”### “这样可以识别的日期格式,对于这种文件,我建议以上、下”—“间所包含的日期作为识别日期。
6. 有时,我会将多日的日记进行合并,其基本结构为”### 2021.9.1 - 2021.9.2",以" - “为连接。对于这种日记,如果存在另一份以"Diary_“为开头的文本,其内有”### 2021.9.1”,“### 2021.9.2"这样的分日的日记,请以后者作为当日的内容。举例,在"Diary_2015"文件中有”### 2015.1.13 - 2015.1.28 拉萨旅记"这种粗糙的日记,但在另一份"Diary_2015_西藏旅记"文件中,有每日的信息,如"### 2015.1.13 启程"、“### 2015.1.14 北京”,生成数据框时,以这些逐日的更精确的内容为准,而不是以"### 2015.1.13 - 2015.1.28"这样的数据。
我的日记撰写规则,你是否能够理解?如果理解,请开始。
Round 2
指令:很好,已经能够读取,但我注意到存在两个问题。
第一,读取存在重复日期,如2015.1.13 - 2015.1.28 拉萨旅记,与2015.1.13、2015.1.14等,如果存在逐日内容,请以逐日为准,如果不存在逐日内容,请拆分为每日,但共用一个内容。
第二,请将日期、日期后题目、该日期下内容,三者进行分离,目前日期与日期后题目是合并的。
Round 3
指令:这段代码运行良好。有两个进一步需要改进的地方。第一,如果某个文本使用了默认日期,且在该日期下的内容,存在以(一)或(二)为开头的文本,则他们都是这个日期下的内容,请对这种数据进行合并,仅保留一个日期;或者说,如果某日content中存在(一)、(二),对于这样的日记,应使用元数据中的日期。第二,如果某个文本使用了默认日期,那么他的title是元数据中的文章标题。
Round 4
指令:重复Round 1指令。并新增如下:我将提供你一个初步的录入代码,但这个代码存在两个问题,第一,如"2019.1.1 - 2019.1.7"这种多日期日记,没有被正确处理。第一,他们与单日数据合并了;第二,部分没有识别日期的文本,没有使用默认的meta日期,以至于丢失了。
Round 5
指令:重复Round 1指令。并新增如下:我将提供你一个初步的录入代码,但这个代码存在一个问题。如果以"Diary_2014"这样数字结尾的文本,以及以"Diary_+非数字结尾"的文本,我希望你能够使用后者的该日内容,作为该日日记。并请输出哪些日期存在重复记录。
我将向你提供一个范例文本,名称为“Diary_2015.md”,在我上传后,请开始调整代码。
Round 6
指令:我注意到有些要求没有满足,在我提供给你的代码中,多期日记被正确识别了,但你反馈的代码,虽然修订了优先使用文本后缀的md文件,但多期日记的首日被错误识别了,即,你使用了数字后缀的md文件。我的建议是,识别日期时,排除文件的md后缀名。
二、文档数据:单日期录入
Round 1
指令:现有多个年份的markdown格式文档,我希望对这些文档进行文本分析。在开始分析前,我要解决录入问题。我将向你提供必要信息,我说“请开始分析”后,请你开始,你理解了么。
首先,这些文档遵循一定的书写规则,我将提供给你相应的书写规则:
1、我希望文档名称排除以“Diary_”为开头的。
2、每份文档,文本的开头均有上、下两个“—”,被包含的内容是文本的基本属性,包括如tags、date等。请记录每份文档的title、categories、date、tags。
3、每份文档遵循,内部有“# ”或“## ”或“### ”作为一级的小标题,以第一个出现的格式,作为该文档的一级标题,我希望你能够区分出每一份文档内部一共有一级标题,几个二级标题。
4、在上述标准外,文档名称为“C_Prose_博客日志”、“M_Prose_统计暨编程问题日志”的两份文档,请将这两份排除在外。
其次,我将向你提供一个文档示例,你读取后,不需要你展示结果,我需要你提供我可以本地运行的r语言代码。请开始分析。
Round 2 迭代Round 1
指令:我检查发现,categories没有被读取成功,我向你抱歉,需要补充信息。部分文章存在两级分类,举例:
categories:
- Health Studies
- Mortality Studies
对于这种分类模式,我希望你能够按第一行为一级分类,第二行为二级分类,分成两个变量。同时,tags是类似的结构,请截取前三位,列为三个变量tag1、tag2、tag3。
Round 3 读取log文档
指令:我现在有多个年份的文档,我希望对这些文档进行文本分析。在开始分析前,我将向你提供必要信息,首先,要解决录入问题。这些文档遵循基本一致的书写规则,我将提供给你相应的书写规则:
1、需要被处理的文档名称为“C_Prose_博客日志.md”、“M_Prose_统计暨编程问题日志.md”
2、两份文档均为按日期记录,请以文档内“### ”开头后的日期与内容,作为日期date与每日的title;
3、“### ”标志的下一行是该日的内容content,天与天的"### “之间均空一行,以进行分离。
4、此外,有时使用了图片或其他超链接,会有空行出现,但每天的日记是以”### “为标准的;有时使用”#### “作为每日日记的二级标题,但这仍然隶属于该日内容;有时部分以”### "为开头的日期不含标题,请以空白处理。
5、每份文档的开头均有上、下两个“—”,被包含的内容是文本的基本属性。包括如tags、date等,请忽视这一部分。
6、路径地址为setwd(‘/Users/yuteng/Blog_Hexo/source/_posts’)
7、最后请以dataframe格式返回,列名分别为date,title,content
不需要你展示结果,我需要你提供我可以本地运行的r语言代码。请开始!
Round 4 分析content中标题数
指令:现有数据中的content变量,内部有“# ”或“## ”或“### ”作为一级的小标题,因为是单独一行,它通常也会与\n前后出现。现在,请以每个content中第一个出现的格式,作为该文档的一级标题,我希望你能够区分出每一份文档内部一共有一级标题,几个二级标题,以及几个三级标题,并以title_level1至title_level3为变量名。
三、数据分析
Round 1
指令:我将提供一份样例数据,请帮助我以r语言进行文本分析,完整数据是2014年至2024年的逐日数据,我希望获得:
1、类似于 GitHub 贡献热力图的可视化,其中横轴表示月份,纵轴表示一周的每一天(从周一到周日),并且颜色深浅表示活动的多少。
2、逐季度的content的文本总量统计,请通过ggplot2绘制为逐季度的折线图,如果某月没有值,则使用NA,并在图中跳过。
3、基于中文分词,统计逐年的前10个词频,并绘制并排的词云图。
4、基于每日content,进行逐年的情感分析,尤其关注正向、负向比重的变化,并绘制为逐季度的折线图。
Round 2 按具体绘图逐个迭代
此处的代码迭代比输入数据要简单很多,不再赘述。举例如绘制词云时:
指令:我希望能够进一步美化,字体使用仿宋体,颜色使用更具审美的,并且能够将工作目录中的wordcloud_1至wordcloud_9合并为一张图。
很凑巧,我一朋友Miss Huang,刚好在我写完这篇时,在微信朋友圈发了这样的段子:“老板给我一个包含几十张表的Excel,我这辈子都没见过这么脏乱的数据。每一张表都像几百张便利贴缝到一起的百家布,比如有些是一整张表只有一列但是无数空行,或者是分隔符用逗号冒号空格换行什么都有。我说两天搞不定,老板说那喂给GPT去洗,因为这样我们项目就是运用了人工智能的项目。但python读不了这么脏的数据,于是我现在在绝望地给AI手洗数据,以便它可以给我老板洗数据。朋友们,这就是荒谬的人工智能的下沉年代。” ↩︎
调用百度智能云自然语言处理中的情感倾向分析接口,约八元。
现有的中文情感分析一般要调用大模型来识别,本地识别错误率仍较高,等有时间调用接口解决。一个猜测是情绪与字符数呈相对一致的变化。↩︎NA为调用了网易云播放器的HTML语句,仅3日,因此在实际分析中均被剔除。另仅有1日未识别,原因待排查。 ↩︎
本文文档数据全部遵循Hexo框架格式,举例如文档meta中包括title、categories、tags、date等信息,在一致的格式下,相关处理代码可简易复现。 ↩︎