Prose_我的画像:使用ChatGpt 4.0辅助文本分析
我一直想对自己的日记与博文做一个系统的定量分析,但限于精力,始终未抽出功夫。最近稍有空闲,即着手做了这件事。如果说一个人的精神发育史就是他的阅读史,那俏皮些讲,对自我文字痕迹的分析,亦无妨视为是对自我的民族志。从2015年至2024年,近十年的分析跨度,基本反映了我本科以来的思想变化。本文全部代码可复现,见文末。
我的画像:博文与日记
鉴于博文(Post)与日记(Diary)不同,前者包括日记,系全部博客文章数据,后者仅指Diary类别下日记数据,如下统计图均为分别绘制,后不再赘述。
一、数量:博客的逐日 / 逐季度活动强度
本节绘制了博文、日记的逐日与逐季度活动强度图,按字符数计算,共四张。2020年的活动强度十分明显的高于其余年份,较前两年大幅回调,但整体上,随着年龄增长,我的吐槽欲望写作强度有明显下降。
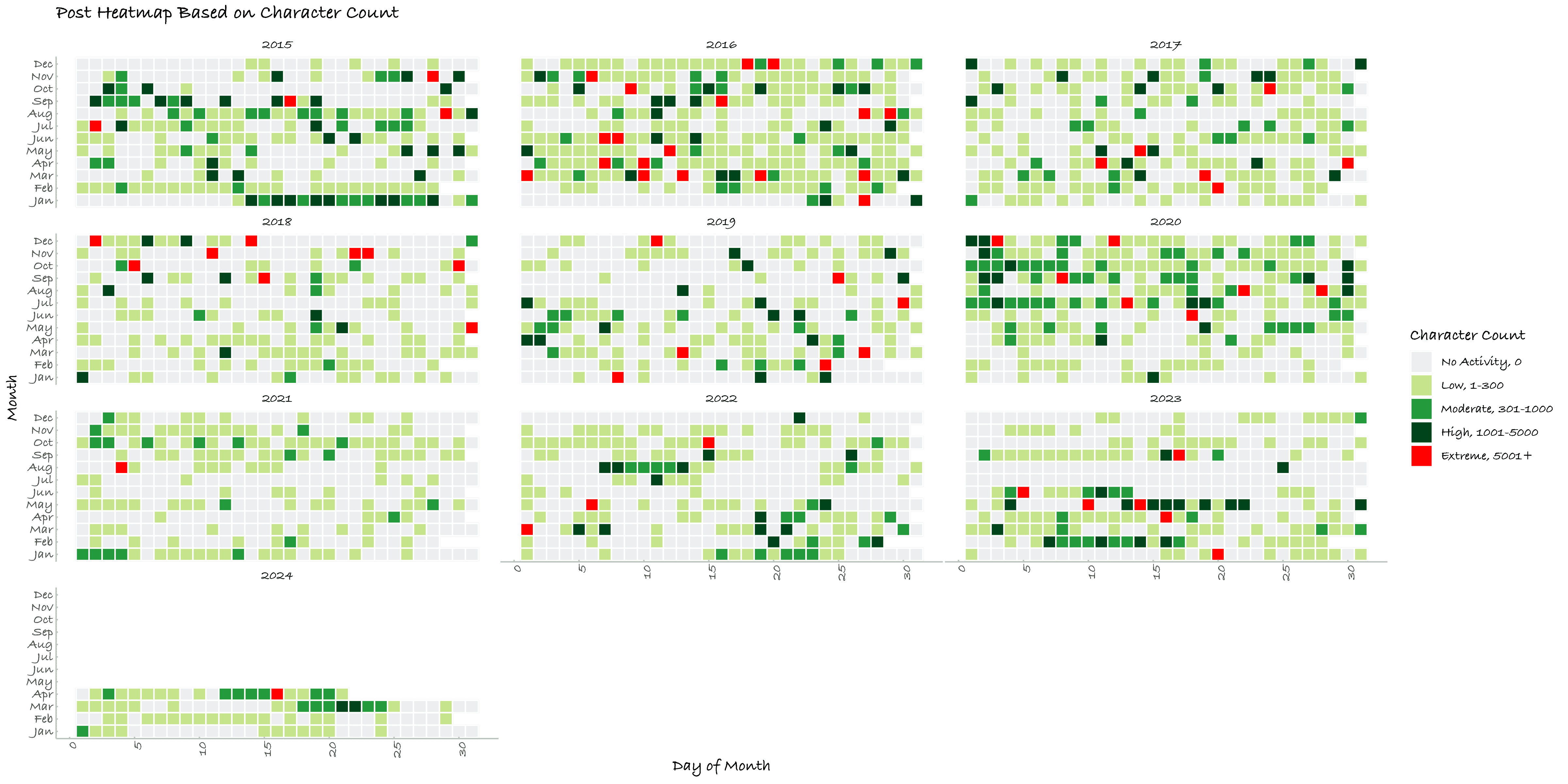 Figure 1. 博文逐日活动强度
Figure 1. 博文逐日活动强度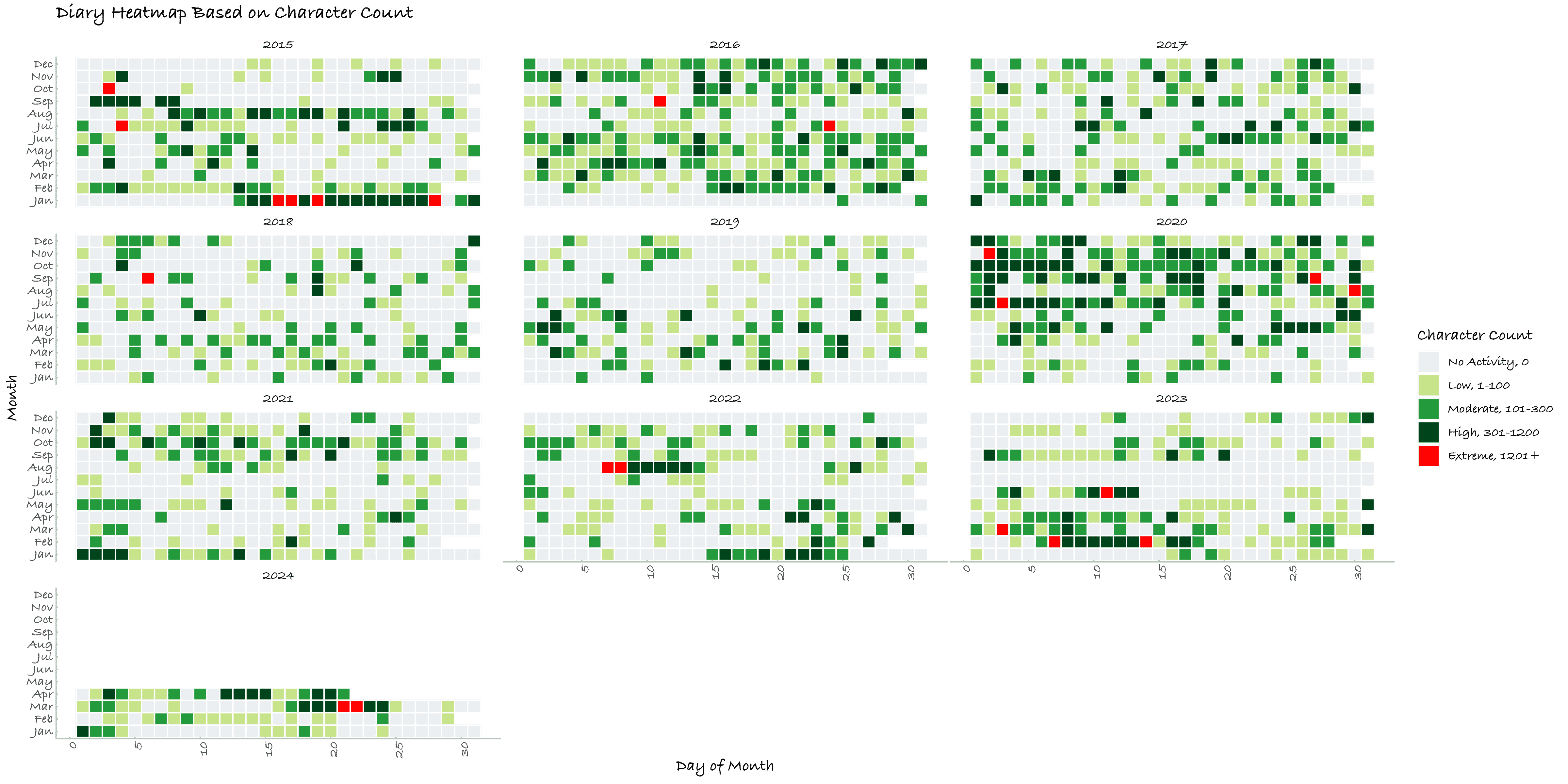 Figure 2. 日记逐日活动强度
Figure 2. 日记逐日活动强度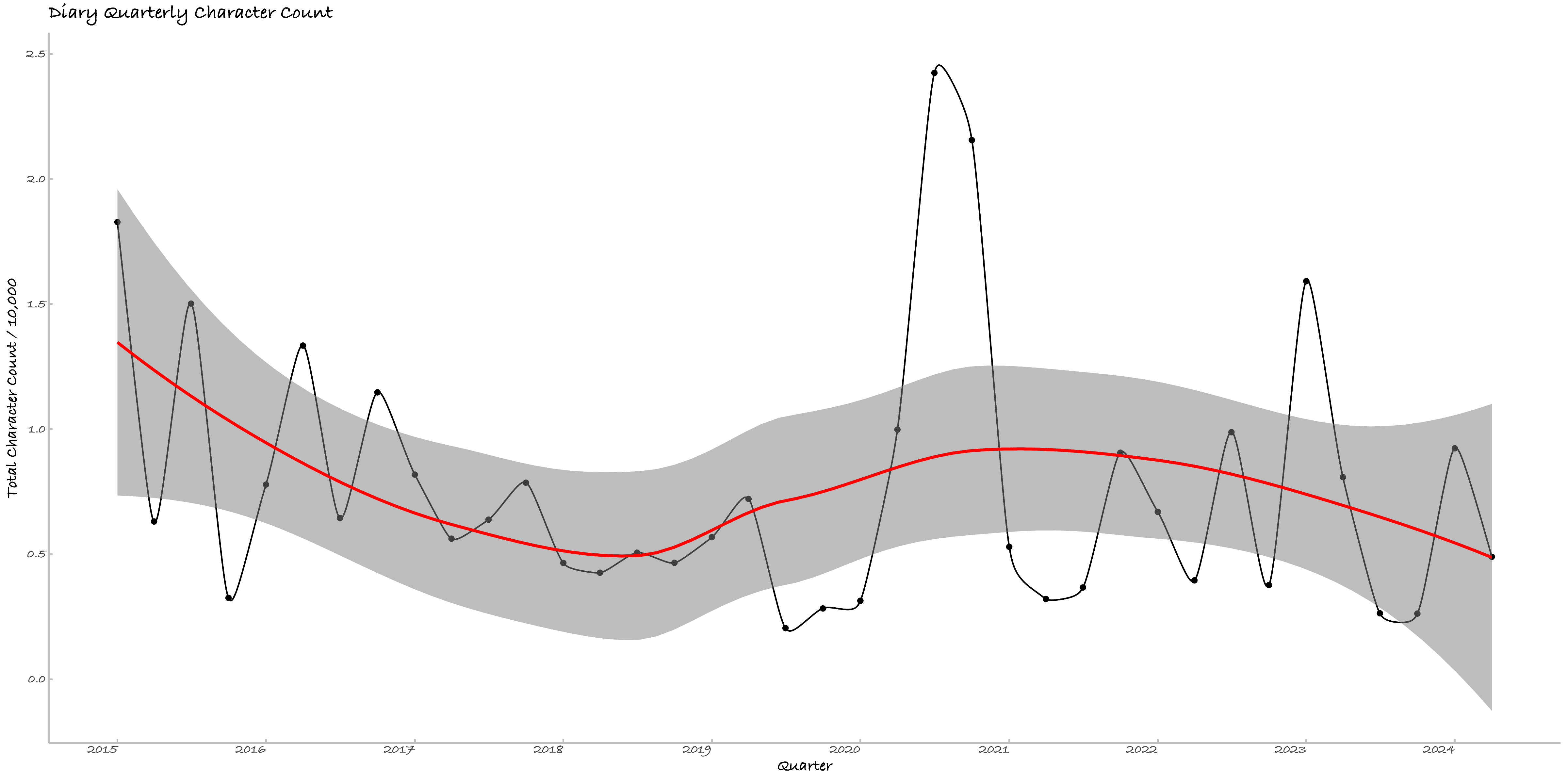 Figure 3. 博文逐季度活动强度
Figure 3. 博文逐季度活动强度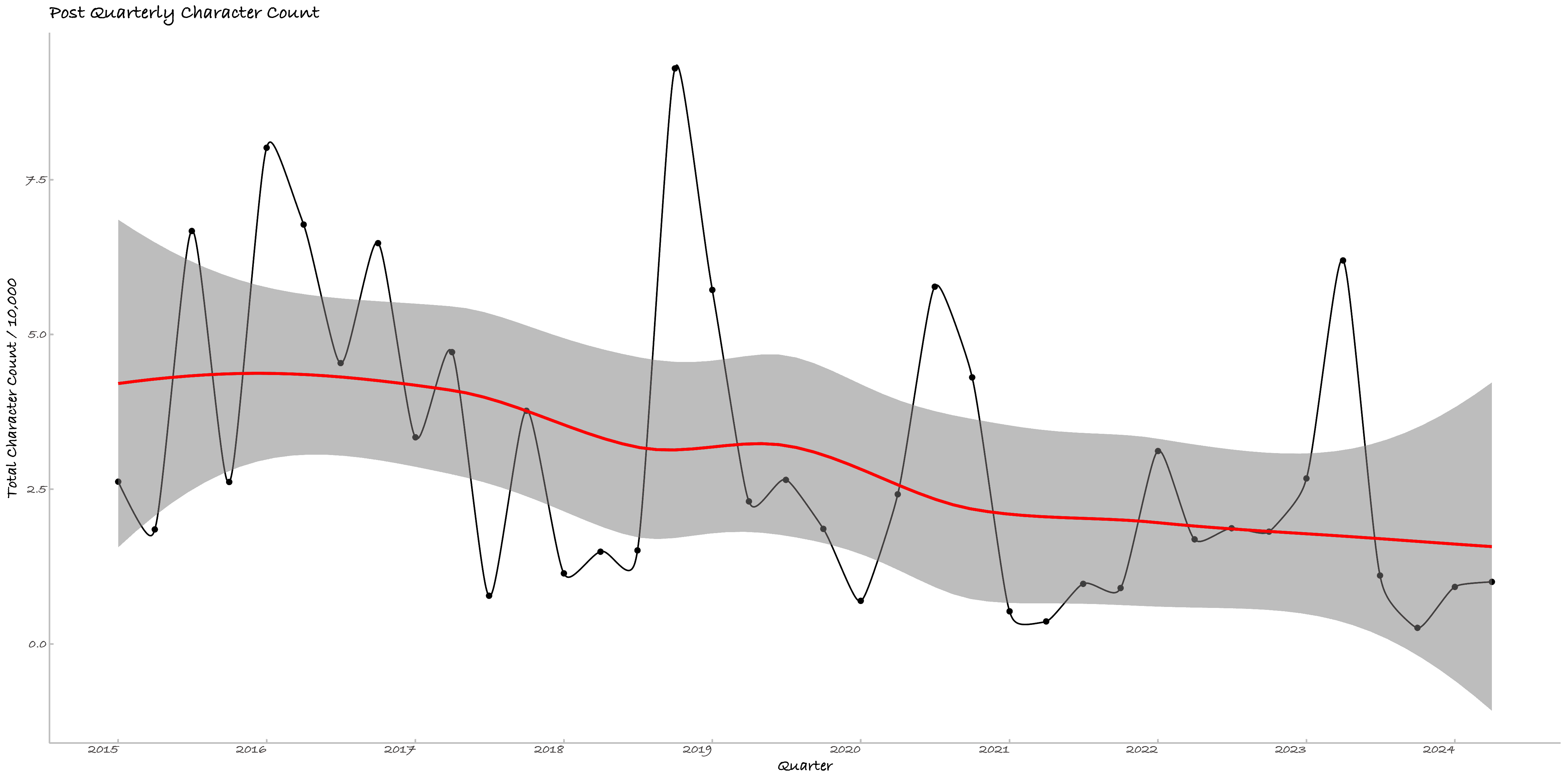 Figure 4. 日记逐季度活动强度
Figure 4. 日记逐季度活动强度二、情绪:日记的逐季度情绪均值
本节调用了百度情感分析接口[1]以分析日记情绪变化,剔除NA后[2]有1503日被有效识别。按-1为消极、0为中立、1为积极,下图是我的情绪变化。数据化的情绪变迁与我的心理日程基本符合。
有三个有意思的事情,其一是情绪倾向比我预想的要积极很多,这可能是因为百度识别的误差,但也说明俺还算阳光男高!其二是与逐日活动的对照很有意思,2020年的偏消极的情绪与较多的记录,确为难忘的一年。
其三可单列一段,我对季度情绪均值与季度字符数及其二次项拟合,模型显示截距项显著、二次项模型边际显著。截距显著说明情感均值不为零(这不废话嘛!)。二次项的显著性(P值 = 0.092)让我不得不面对一个可能的残酷现实:快乐的男高越写越悲伤(或许我在搬砖),或者是越悲伤的诗人越勤奋(诗人我穷而后工?)。这段情感的起伏与字符数的关系可以用以下的二次回归方程来描述:
| 参数 | 估计值 | 标准误差 | t 值 | P 值 |
|---|---|---|---|---|
| Intercept | 0.2882 | 0.1236 | 2.331 | 0.0256 * |
| character_count | 0.3945 | 0.2691 | 1.466 | 0.1516 |
| I(character_count^2) | -0.1919 | 0.1108 | -1.732 | 0.0920 . |
其中 是以万为单位的字符数。根据模型,我的情绪均值首先随写作量的增加而上升,但达到某个临界点后,就开始走下坡路了。好像我的人生一样。峰值的计算显示,当字符数达到约 万时,我的情绪均值达到最高点约 。超过这个点,每增加1万字符,我的情绪均值降幅可以描述为:
考虑到情绪均值的区间是,这样的变化幅度确实挺大。科学的、历史的数据提醒我,当我每季度的日记字数接近1万时(大约每天113字),就可以摸鱼了!如果工作量超过每日100字,我就会开始疲倦。果然开摆的人生才是我的归宿。
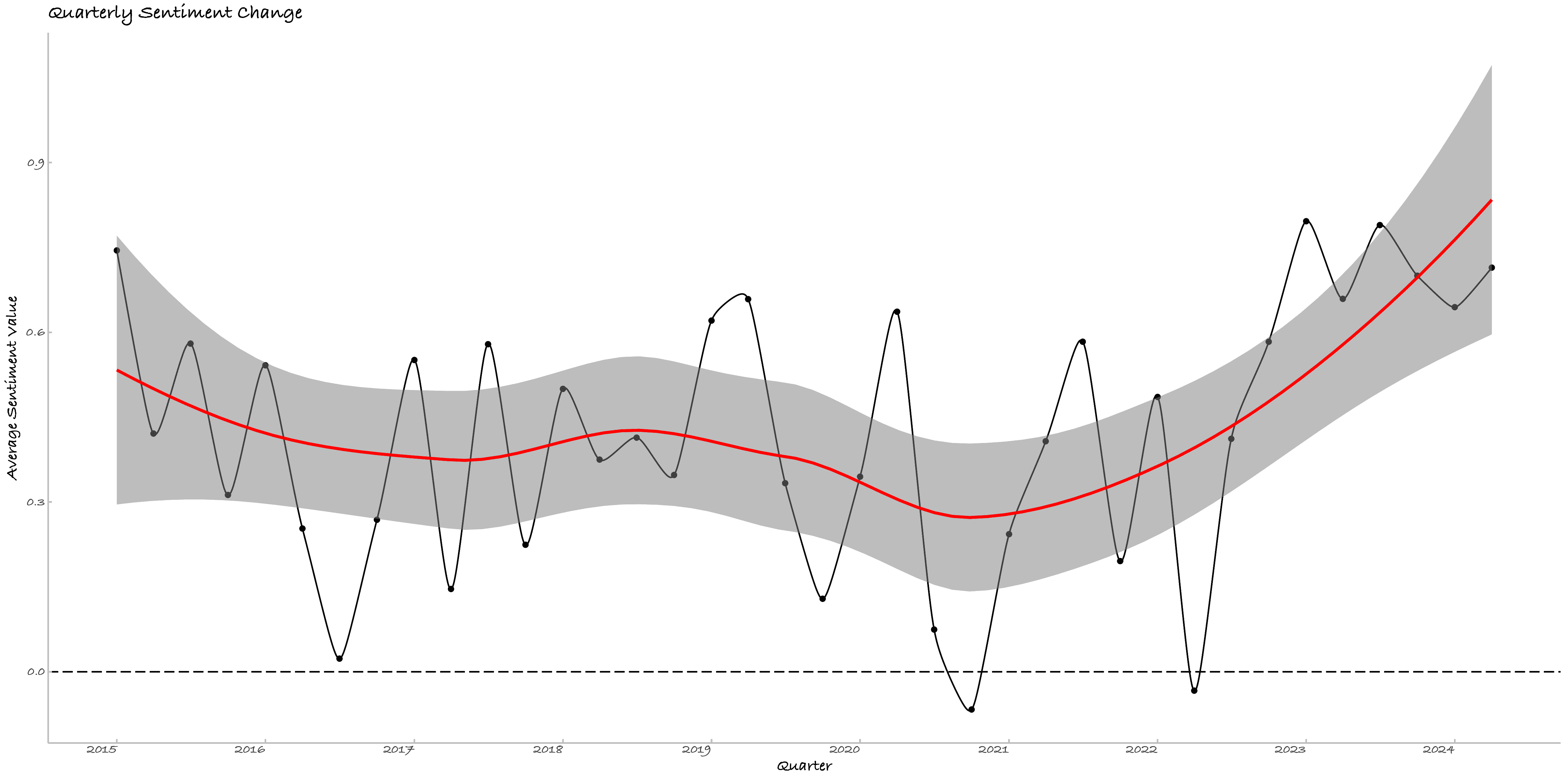 Figure 5. 日记的逐季度情绪变化
Figure 5. 日记的逐季度情绪变化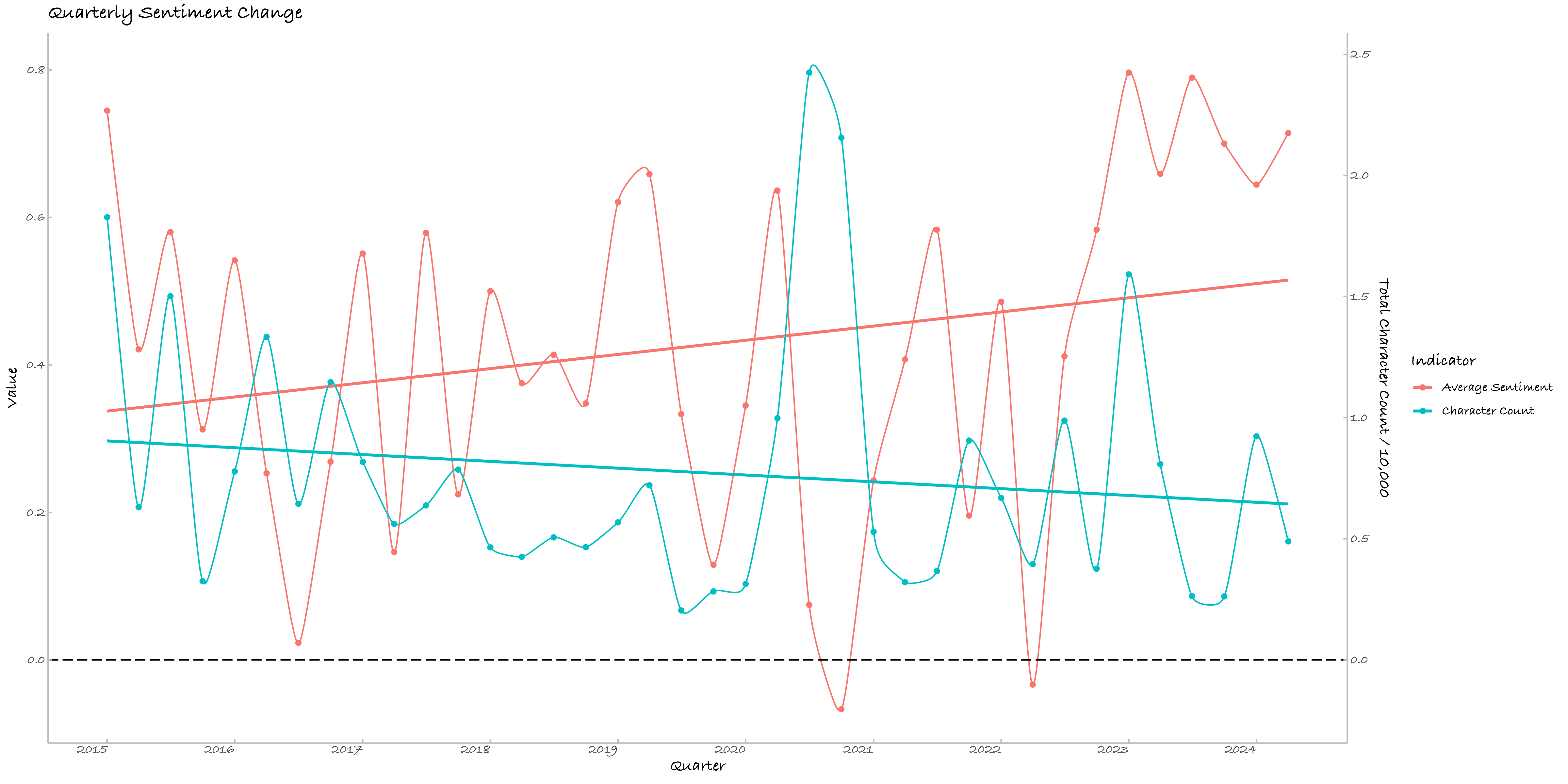 Figure 6. 日记的逐季度字符数与情绪值拟合线
Figure 6. 日记的逐季度字符数与情绪值拟合线四、词汇:博客的逐年关键词
本节绘制了逐年的博文关键词与日记关键词。明显区别是学术梦碎2024。近两年关键词的变迁很好地反映了我的关注点变化,其一是从社会学转入人口学,其二是业余生活因在京畿地区,参览了很多的古建筑和佛造像。
四月廿四日晚,我和孙畅亦聊起我这两年的转变,其一是将工作和生活分开,其二便是我的审美会追求一些永恒性的东西,佛造像及其背后的文化,在人类个体短暂的生命尺度里,是一种具有永恒性价值的地标,尽管这一地标及其内涵在不断流变。
 Figure 7. 博客的逐年关键词
Figure 7. 博客的逐年关键词 Figure 8. 日记的逐年关键词
Figure 8. 日记的逐年关键词五、地图:博客的逐年旅行足迹
本节绘制了逐年的旅行地图。2015年以后,我的大部分旅行都会撰写一份对应的旅记。原本旅行地图放在简介/About中,但俺感觉简介像裹脚布一样又臭又长,挪在这里似乎更合适。
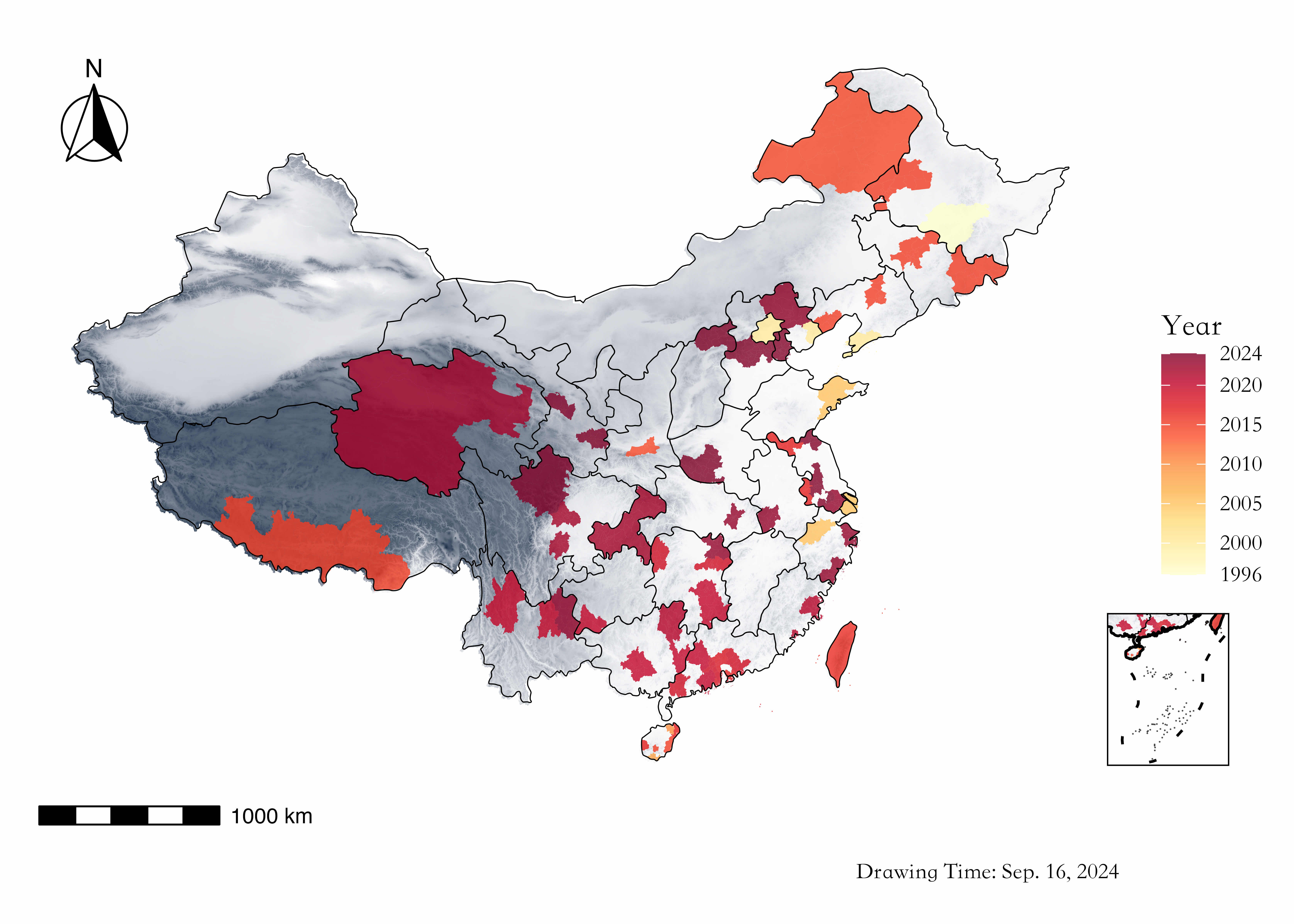 Figure 9. 博客的旅行地图
Figure 9. 博客的旅行地图六、阅读旨趣:博客的分类统计
本节绘制了汇总的博文分类图与标签统计图。
前者按Figure 10与Figure 11,基本反映了我的阅读兴趣。如果加入时间因素,大概我早期的阅读兴趣是都市社会学,最近两年转为健康研究方面,阅读兴趣的转变或可以参照我六年前的自陈与一年前的书单。(六年前好遥远哦!)
后者按Figure 12,数量排在前三位的tag系一级tag,是互斥的book、prose、paper,再加上未被列入的log(2篇),就是我的全部博文数量。数据反映了我的写作内容是围绕着书、随笔以及论文展开,其中关于书的讨论是最多的。除这三个一级tag外,二级tag因并非按互斥设计,仅供参考。其中,我在中国南方的旅行有最高频数,其次是阅读时留存的部分译文,再次是我对当代史、资本主义、转型理论、治理、阶层、计量模型等主题的相关阅读或评议。
注:很多博文我没有打标签,该直方图仅供参考。一级tag为互斥组,二级tag允许重叠。
俺的自我分析到此结束,鼓掌!撒花!感谢好兄弟的阅读!题外话,Figure 10 - Figure 12的配色是杏仁白(Almond White)色谱,鸡尾酒里我也很喜欢杏仁酸(Amaretto Sour),看到这篇博文的朋友,有机会俺可以请你一起喝酒!(博士生的出路:体育? 酒鬼!√)
ChatGpt日志与代码
这篇分析的一个特殊处,是我没有主动coding,大部分的代码工作(80%以上)是ChatGpt 4.0所完成的。按照社会科学的培养模式,我认为其代码能力已不输于很多优秀院校的高年级本科生,作为学术助手,能够极大简化枯燥的数据处理流程。当然,现阶段的大模型仍然存在一定问题,比如在数据分析时,Gpt自行发挥的结果往往不符合预期,更重要的是通过Prompt反馈Gpt我们所需要的图形或模型结果,另如Gpt有时难以处理一些程序报错问题,需要程序外的排查。
事实上,上述也反映了Gpt虽能简化我们的coding工作,但目前的工作流仍是一种人机间持续的反馈与交互过程,这与工业时代依旧存在极大的共通[3]。因而,尽管Latour所讨论的物与人的联接,在形式上似乎更加复杂、多样,但"我们从未现代过”也不算过时。
为了减少阅读负担,我将大部分技术细节略去,对此感兴趣的朋友可以移步至我的Github查看指令迭代文档。更具体讲:
第一,本文/.md数据全部遵循Hexo框架的格式,例如文档meta中包括title、categories、tags、date等信息,在一致的yaml格式下,相关处理代码可下载并便捷复现。
第二,旅行地图数据相对独立,其处理代码与地图数据可下载。因免费版Github LFS有每月1 GB下载带宽限制,地图文件仅被下载3~4次即额满,下载页面转至Coding,如果你不便从Coding下载,欢迎与我联络。
第三,阅读旨趣部分调用了hexo-statistics-charts插件以直接读写网页数据,但我改动了原始脚本。其一,各统计图仅统计一级分类;其二,饼图按数量的由多到少、顺时针排序,雷达图仅列出文章数量前五位的分类;其三,各统计图色谱均修订为杏仁白(Almond White)色谱,与博客整体色调保持一致,且增加分割线与阴影效果[4]。如需复现我改动的js效果,下载后替换./node_modules/hexo-statistics-charts/index.js文件即可。
俺的杏仁白色谱如下。
'#45222D', /* 深棕色 */ '#6A3A2C', /* 较深棕色 */ '#8F5348', /* 中棕色 */ '#B66C65', /* 较浅棕色 */ '#D78584', /* 浅棕色 */ '#F2A0A0', /* 更浅棕色 */
'#FFB59B', /* 杏仁白 */ '#FFE6C9', /* 浅杏仁白 */ '#FFDAB9', /* 非常浅杏仁白 */ '#F8D7C4', /* 极浅杏仁白 */ '#E6D3CC', /* 灰杏仁白 */ '#D4CFD4', /* 灰白色 */ '#C2CACD' /* 浅灰色 */
脚注
调用百度智能云自然语言处理中的情感倾向分析接口,约八元。
现有的中文情感分析一般要调用大模型来识别,本地识别错误率仍较高,等有时间调用接口解决。一个猜测是情绪与字符数呈相对一致的变化。↩︎NA为调用了网易云播放器的HTML语句,仅3日,因此在实际分析中均被剔除。另仅有1日未识别,原因待排查。 ↩︎
很凑巧,我一朋友Miss Huang,刚好在我写完这篇时,在微信朋友圈发了这样的段子:"老板给我一个包含几十张表的Excel,我这辈子都没见过这么脏乱的数据。每一张表都像几百张便利贴缝到一起的百家布,比如有些是一整张表只有一列但是无数空行,或者是分隔符用逗号冒号空格换行什么都有。我说两天搞不定,老板说那喂给GPT去洗,因为这样我们项目就是运用了人工智能的项目。但python读不了这么脏的数据,于是我现在在绝望地给AI手洗数据,以便它可以给我老板洗数据。朋友们,这就是荒谬的人工智能的下沉年代。” ↩︎
题外话,该插件也提供Github逐日图,但仅能够统计文章数量、无法合并历年活动。没有R画的好看。 ↩︎